In this article we’ll look at a few simple techniques which can really supercharge your Java project and make them much easier to work with!
- Semantic Versioning
- Conventional Commits
- Time for Magic
- Creating the Initial Release
- Go Forth And DevOps
- The Gradle Version
- That’s It
tl;dr If you know the concepts, then just jump straight to my fork of standard-version at github.com/dwmkerr/standard-version. It adds support for Java projects. I am currently trying to get it into the mainline, so if you like this, please comment on the Pull Request here. tl;dr end!
Semantic Versioning
First, let’s talk about the idea of a Semantic Version. A semantic version is nothing more than a versioning scheme you will probably be familiar with, where versions look like this:
1.2.3
The only thing special about a Semantic Version is that we give a very specific meaning to each part of the version. In short:
1is the major part of the version2is the minor part of the version3is the patch part of the version
Now we give semantics (meaning and context) to these parts:
Major
A major version number change means something big has changed, and the API of the software is different to the earlier version. Essentially, this is a potentially breaking change, so you should only use this new version after carefully reading about the changes.
Minor
A minor version number change means that something has been added or changed, which affects the functionality of the code, but in a non breaking way. An example would be the addition of a new API. That won’t affect existing users, so they can generally safely upgrade minor versions without too much risk.
Patch
A patch version number change means something really inconsequential to the user of the code has changed. It might be new documentation, better logging, but it is generally not a functional change.
Why Does This Matter?
If we have Semantic Versions, we can be a lot more sure about when it is safe to upgrade. If we see a major version change, we know we need to be careful. Minor changes might need attention, and patches are almost always going to be safe.
Managing dependencies and keeping them up to date is hard in software development, and one of the reasons people are wary of updating dependencies is that they don’t know if they upgrade will break their code.
Semantic Versioning tries to bring a little order to this chaotic world.
The Semantic Versioning Specification
There is a detailed specification for semantic versioning, which also covers more sophisticated cases, you can find it here:
I’d suggest this is recommend reading for any software engineer!
Using Semantic Versions
Now the easiest way to start with semantic versioning is to simply adhere to the spec! For example, if you make a change which could break something for users, bump the major part of the version.
But, things aren’t all that easy…
The Challenge of Semantic Versions
The challenge is this. Imagine you are cutting a new release of your code and many people have contributed. Some bug fixes, some patches, some documentation. How do you look through all of those changes and decide how to appropriately change the version number?
To solve this problem, say hello to Conventional Commits.
Conventional Commits
If you have a commit history like this:
Updated the users API
Bugfix
trying the build again, got it working
Bugfix: [JIRA-21] fixed that issue
you can now get user's friends with this change
Then it is very hard to reason about what is going on. What about if the commit history looked like this?
feat(users): [#12] fetching users returns their avatar url
fix(users): [#45] display names with emojis return correctly
build(cicd): update the expired deploy key
fix(docs): [#22] fix broken links to the javadocs
feat(users): [#49] users api optionally returns friends, non-breaking
It’s much easier to see what each change means, at least at a high level.
By having some kind of standard for commit messages, we can do a lot. We can:
- Classify changes by type (such as a feature or fix)
- Include a clear description of the change
- Use a convention to indicate a breaking change
- Link to a ticketing system
Just like semantic versioning, conventional commits have a specification too:
https://www.conventionalcommits.org/en/v1.0.0/
Time for Magic
Now if we have conventional commits, and want to use semantic versions, we can actually skip the whole process of looking over a commit history to create a new semantic version - we can automate it.
We can even automate the process of creating a ‘changelog’, a list of each change which comes in each version. There’s an excellent library which does this, called standard-version:
https://github.com/conventional-changelog/standard-version
It’s maintained by the same group behind conventional commits. The only problem? It only works for JavaScript projects (unless you are willing to write custom code which can be complex).
But I’ve updated the library to support Maven projects and Gradle projects, so you can use it for Java now as well!
Let’s see it in action. Here’s a very simple Java library built with Maven:
https://github.com/dwmkerr/java-maven-standard-version-sample
This library has no changelog, no tags, no version data at all except for 0.1.0 in the pom.xml file.
Now if I was to clone the library, make a change and make a commit, which didn’t follow the conventional commit spec, we’ll just see the usual success message:
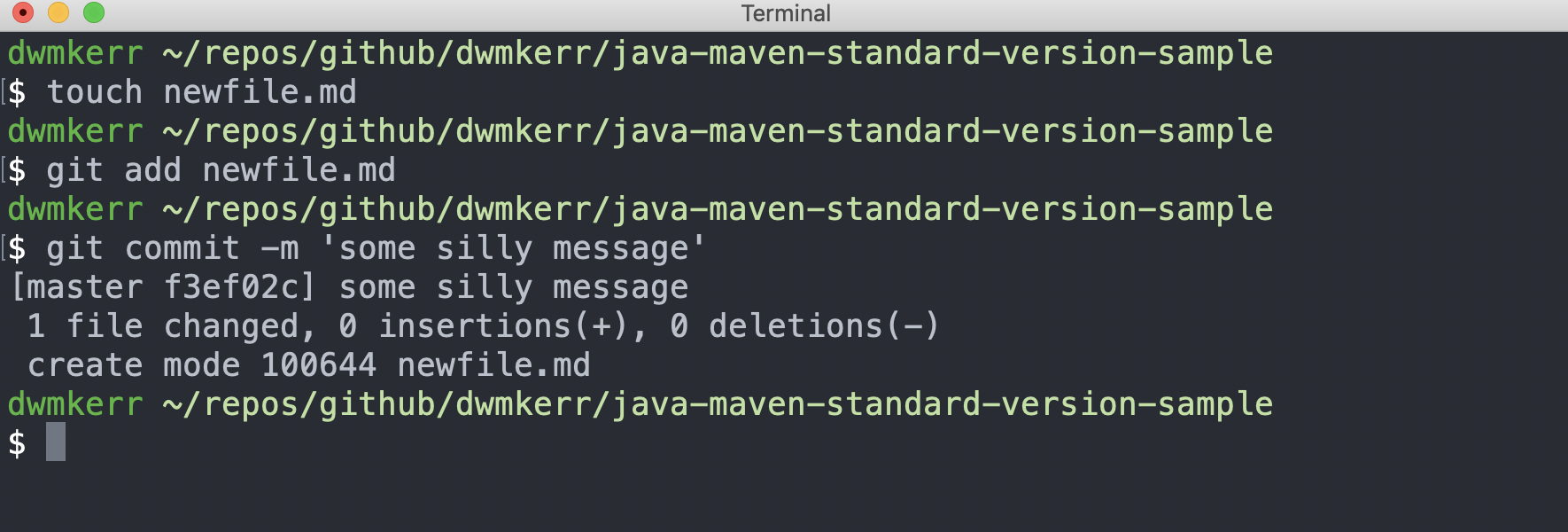
This is a problem; we want to enforce conventional commits.
Enforcing Conventional Commits with Git Hooks
Git has a powerful ‘hooks’ facility, which let you run logic at key points in operations. This is a massive topic on its own, so we’re not going to go into lots of details, but if you are interested you can read about them here:
https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks
Now the issue with Git Hooks is that they are per user - if I add a hook to my .git folder, no one else will get it. We want the same hooks for all users.
There are a few ways to get around this. You can set up server side hooks (which could reject a push if it has an invalid commit message), but this isn’t easy to do (and with some providers, like GitHub for public projects, not even available as an option). Also, we want fast feedback, so if I make a bad commit message, it fails straight away and I can fix it.
The way I suggest getting around this is this:
- Create a
.githooksfolder in your repo - Instruct people to configure the git repo to look for hooks there
That way there are no global changes, only project specific ones. We still need to make sure the developer sets up the hooks though! You’ll notice in my sample project’s README.md file the first thing I do is instruct people to setup the hooks:
git config core.hooksPath .githooks
Let’s see how the same operation would look if we’d setup the hook first:
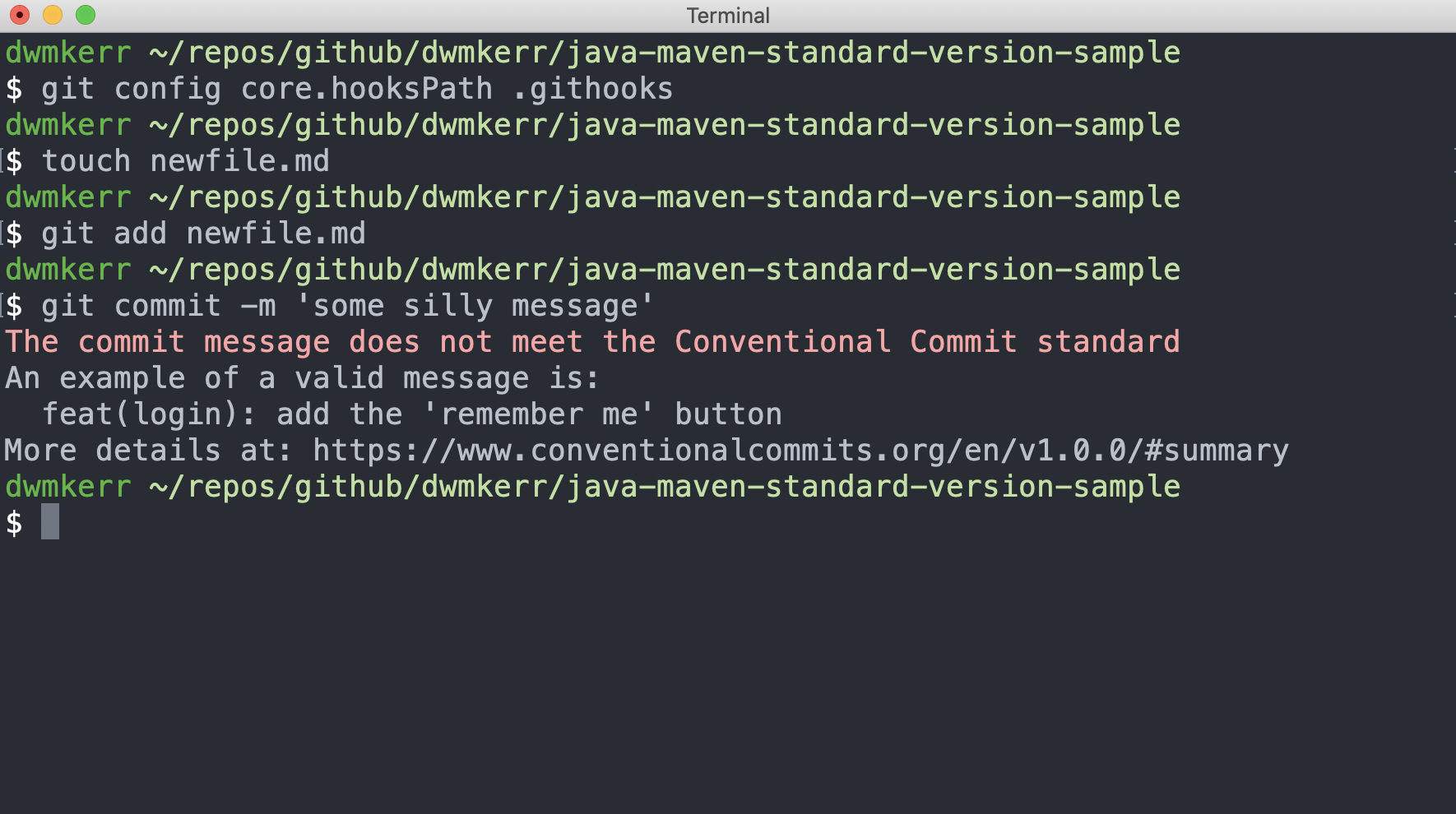
Our hook has fired off and told us we’ve not used a conventional commit message - it even let’s us know where to go to find out more.
Let’s try a message which should work, as it meets the standard:
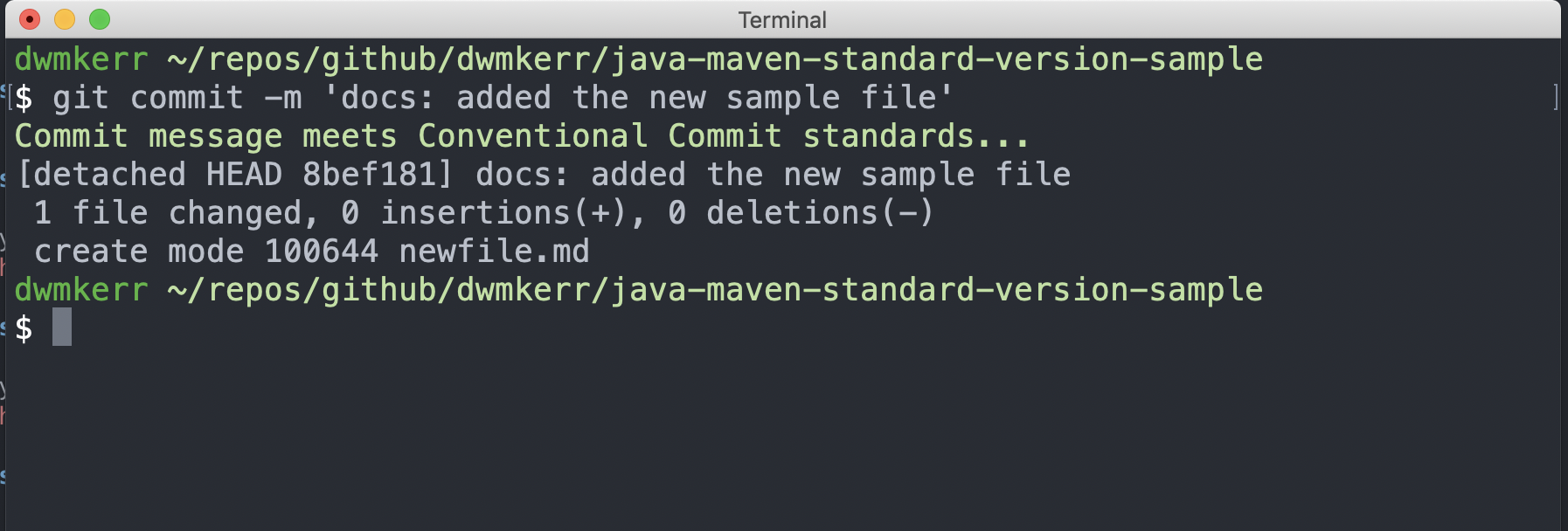
Awesome! We’ve been informed that our message meets the standard (useful to actually remind us that this is being checked!) and the commit has succeeded!
Remember; we only need to setup the hooks once - it’s a one time activity.
How the Hook Works
Hooks are just shell scripts. You can write them in Ruby, Python, whatever. I have written this one in pure Bash because it’s really just checking a regex, which Bash is more than capable of. Also, I can’t be sure the developer will have Ruby or another tool on their machine.
The hook is as simple as this:
#!/usr/bin/env bash
# Create a regex for a conventional commit.
convetional_commit_regex="^(build|chore|ci|docs|feat|fix|perf|refactor|revert|style|test)(\([a-z \-]+\))?!?: .+$"
# Get the commit message (the parameter we're given is just the path to the
# temporary file which holds the message).
commit_message=$(cat "$1")
# Check the message, if we match, all good baby.
if [[ "$commit_message" =~ $convetional_commit_regex ]]; then
echo -e "\e[32mCommit message meets Conventional Commit standards...\e[0m"
exit 0
fi
# Uh-oh, this is not a conventional commit, show an example and link to the spec.
echo -e "\e[31mThe commit message does not meet the Conventional Commit standard\e[0m"
echo "An example of a valid message is: "
echo " feat(login): add the 'remember me' button"
echo "More details at: https://www.conventionalcommits.org/en/v1.0.0/#summary"
exit 1
The only really tricky bit is the regex, and the weird \e[32 type characters which are used to set the colours. You might find it easier to write your hooks in a proper programming language - and for anything more complex I’d suggest that makes far more sense! But if a bit of Bash will do the trick, there’s nothing wrong with that.
As a side-note, if you are into Bash and the shell, check out my online Effective Shell book. git config core.hooksPath .githooks
Creating the Initial Release
Now the chances are, if you are interested in this technique, you’ve probably got an existing project you want to use it on. It probably doesn’t have a changelog or conventional commits. That’s OK, just start from now.
Here’s how we’d start using the standard-version library to manage our versions. I’ve added a new API to the release branch (to keep master clean for people reading the sample) and committed it.
Now lets actually create our changelog:
npx @dwmkerr/standard-version --first-release --packageFiles pom.xml --bumpFiles pom.xml
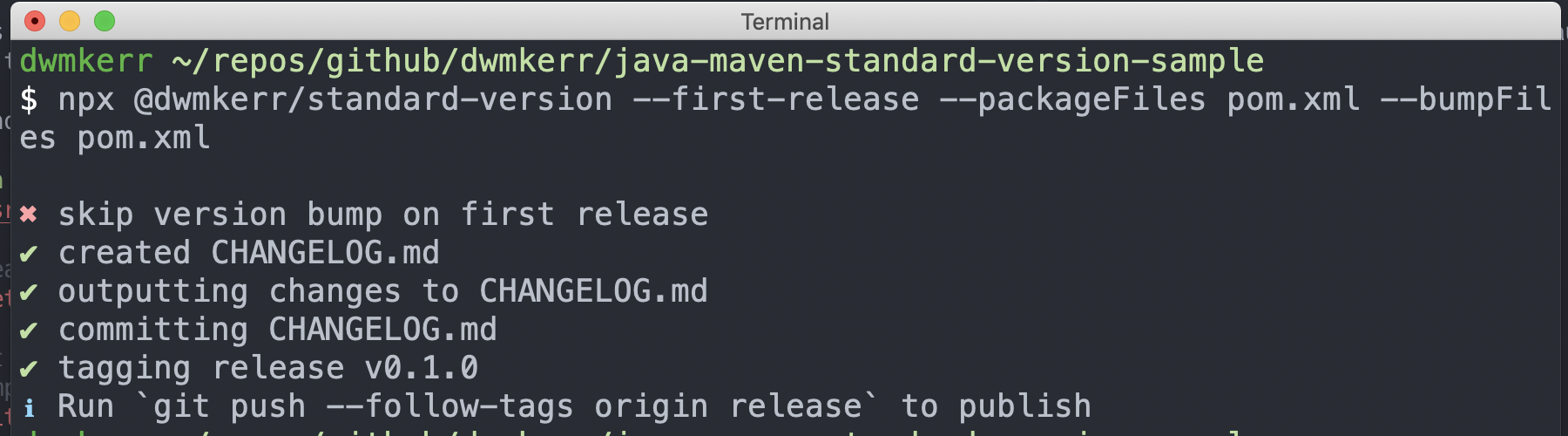
Now it’s a pain I know, but you need Node.js installed for this to work. The standard-version library is built on node, that’s what is used to do all of the logic around writing a changelog and working out what the version bump should be. You also have to use my fork @dwmkerr/standard-version rather than the main version, because at the time of writing my pull request which adds support for pom.xml files is not yet merged.
What has happened here is that the standard-version tool has not changed the version number. We told it this is the first-release, meaning we haven’t published yet, so there’s no need to create a new number. What is has done is given us a changelog and told use how to push the tags and code. If we push, we can now see the changelog:
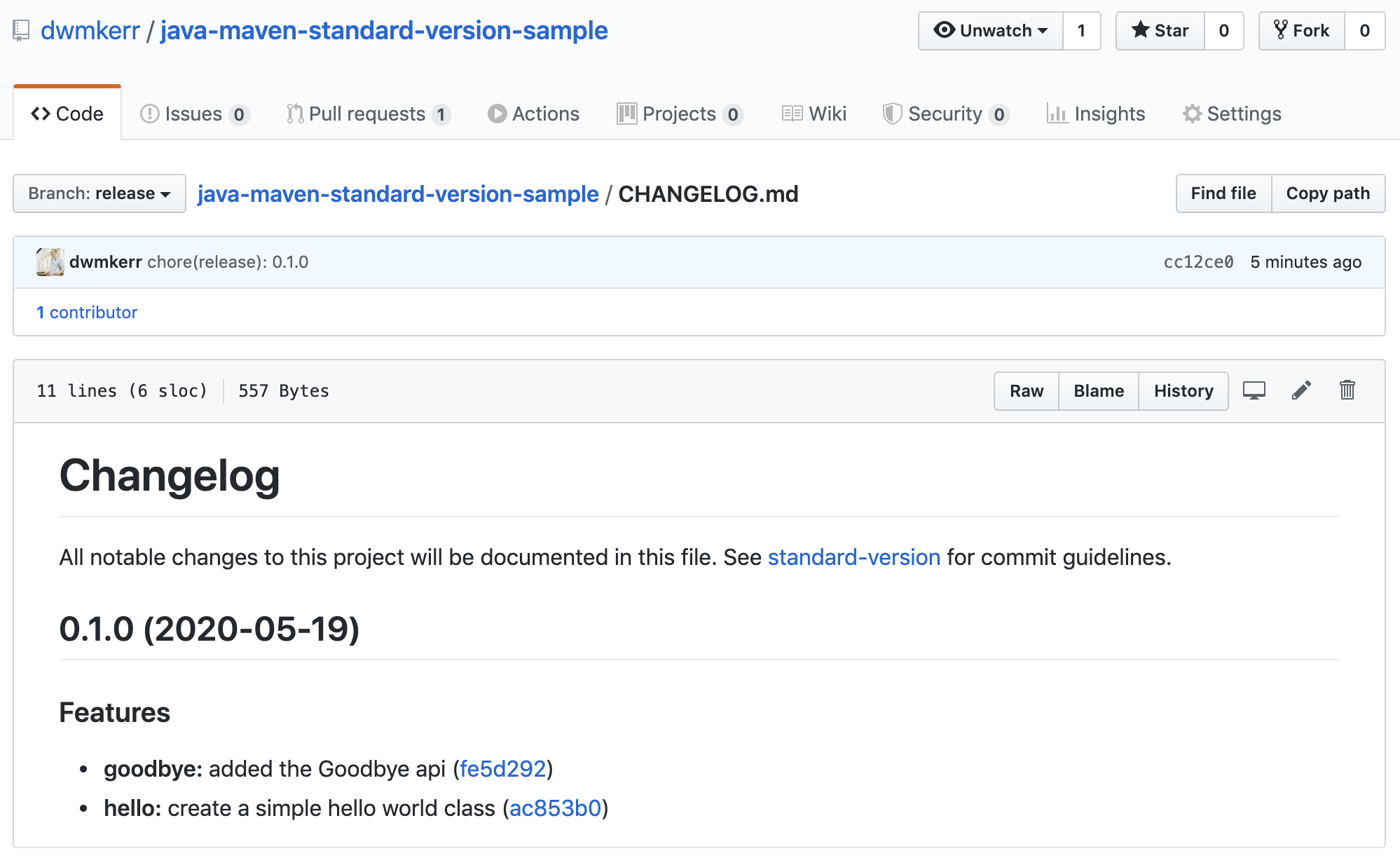
See how we get a changelog showing the changes, the version and the date? We even have links to the commits for each key change!
If we’d linked the message to GitHub Issue numbers it’d automatically have links to the issues too!
Now in this code I deliberately made a mistake - the test for the Goodbye api is a copy and paste of the Hello test! And the Goodbye api has a spelling mistake. Let’s fix this and cut a new release.
I’ve made the change on the release branch, now I’ll run standard-version again:
npx @dwmkerr/standard-version --packageFiles pom.xml --bumpFiles pom.xml
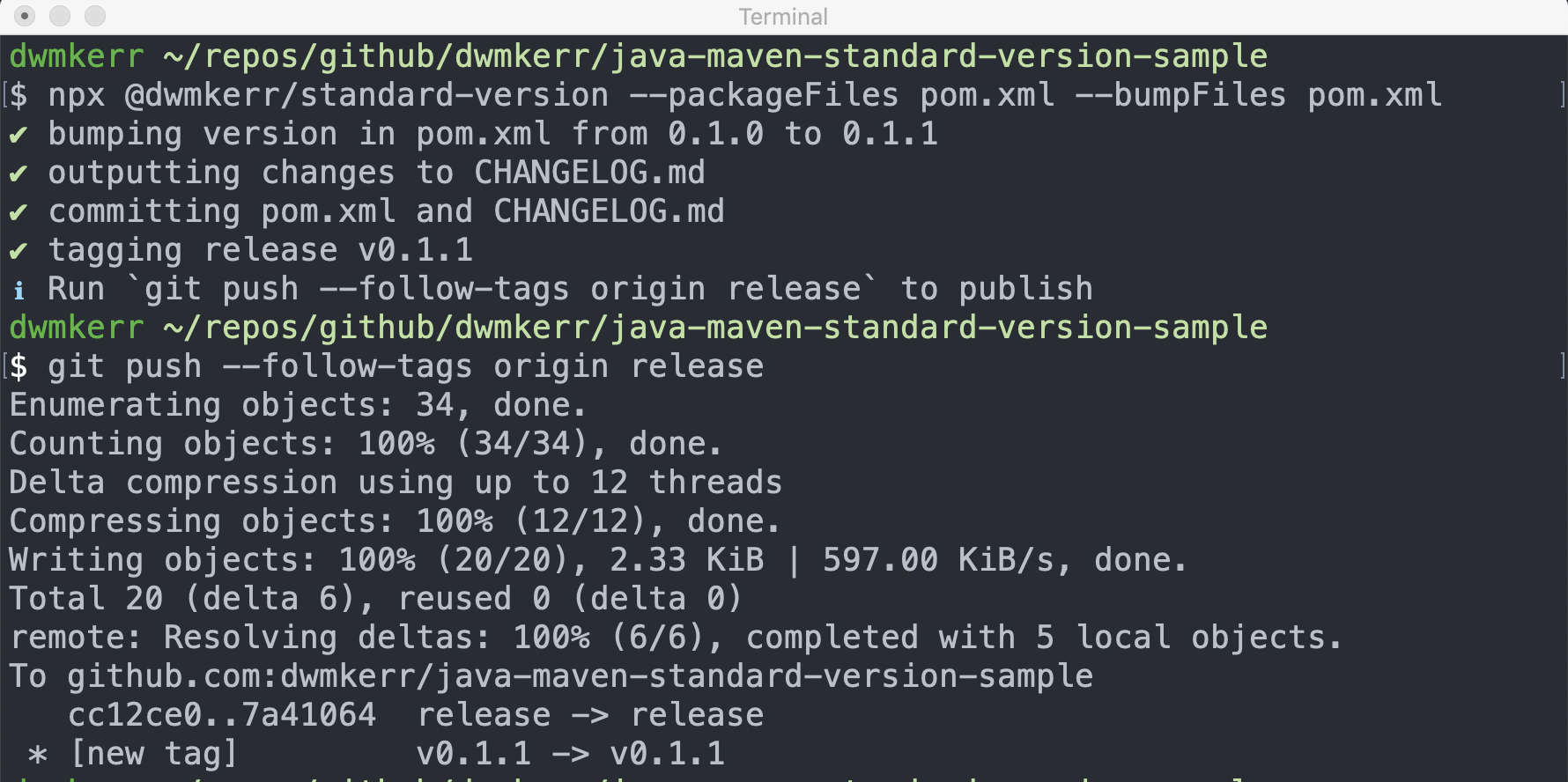
Note that there was no need for the --first-release flag.
Now this time, a new version has been generated. This was a fix commit, so it has made it a minor version bump. If we needed to make it a breaking change, we can use a message with an exclamation after the type, such as fix(goodbye)!: fix the typo. Check the standard-version docs for more about this.
Finally, let’s look at our new changelog:
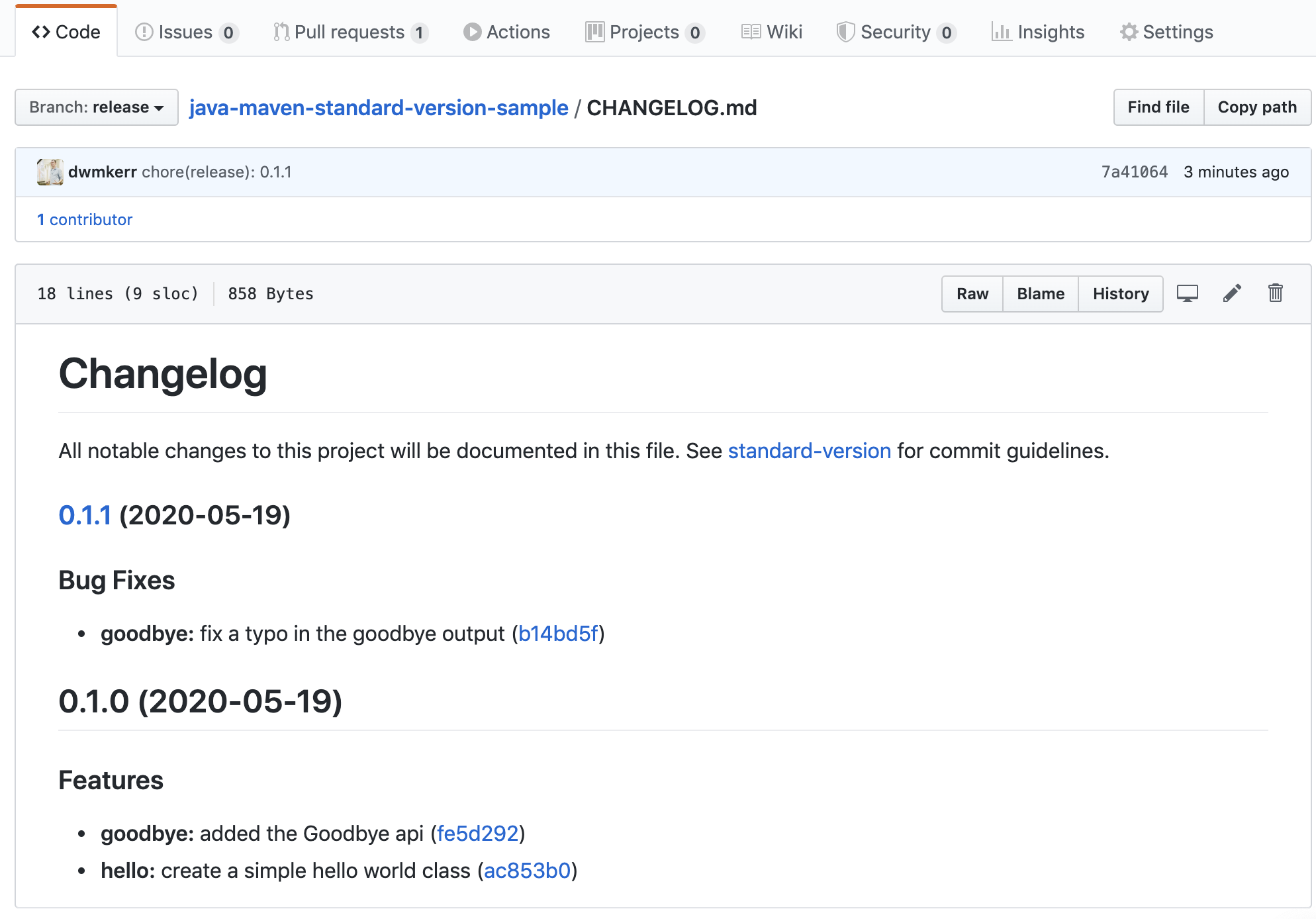
We have even more info now - we have a link to the tag. This is incredibly useful for managing releases.
The icing on the cake? Let’s look at the pom.xml:
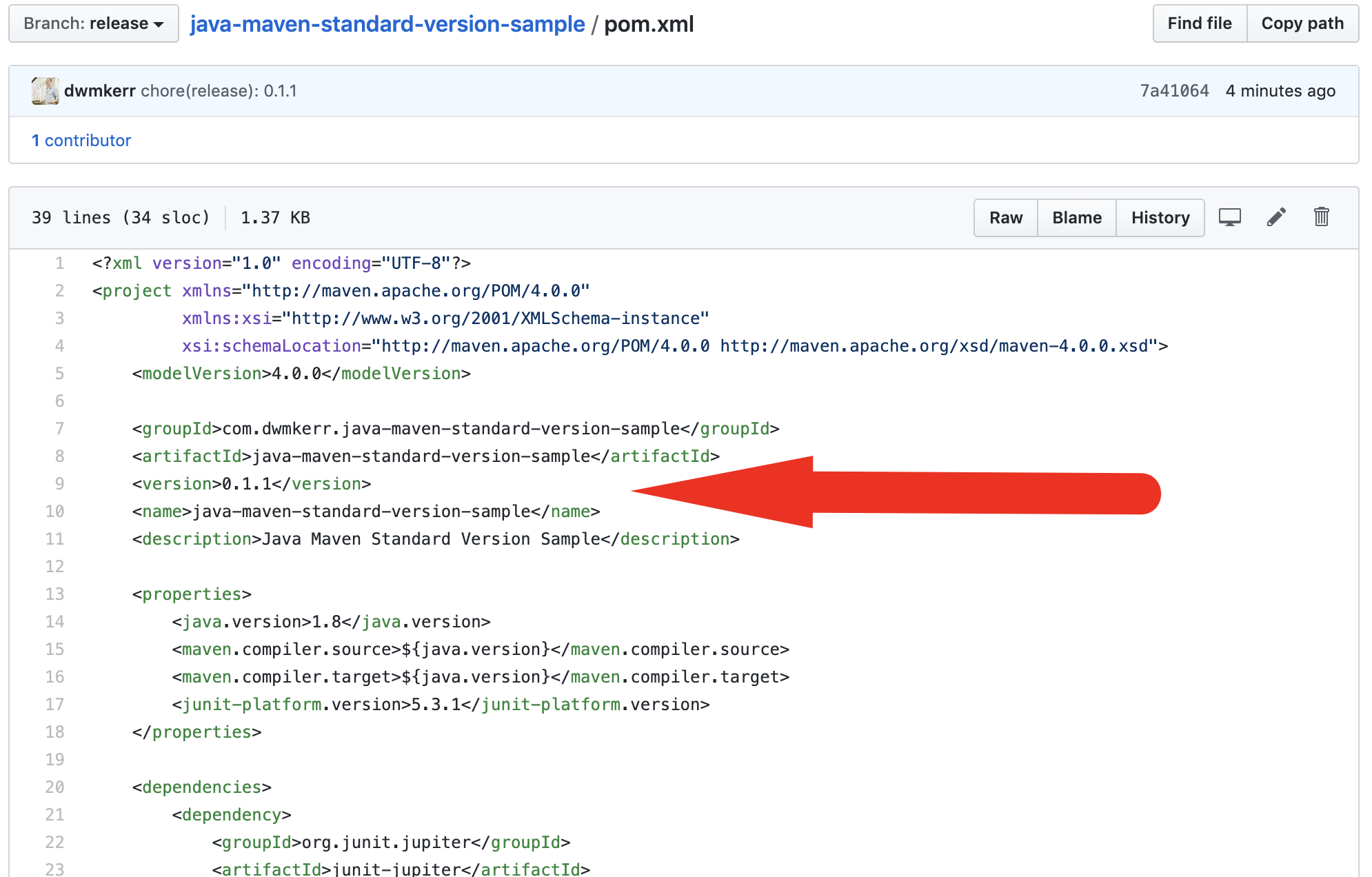
Note that the version has been updated. standard-release is keeping our Git Tags and our Java Library Version numbers automatically in sync.
Once you’ve started doing this and seen it in action for a while, you’ll wonder how you lived without it!
Go Forth And DevOps
This is just the beginning! Think of all the cool things we can do with this in place, here’s just a few:
- Update our build pipeline so that when we merge into
masterwe automatically runstandard-version - Update our build pipeline so that when a new version tag is added, we automatically publish the library
- Send out a slack notification with the changelog when a new version is committed
- Share the changelog with our consumers as our libraries are updated
With these basic building blocks:
- Conventional Commits
- Semantic Versioning
- Enforcing of Commit Standards
- Usage of the
standard-releasetool
We have created a very powerful way to manage what is actually a highly complex process. We’ve introduced almost no additional complexity, just a few guidelines for developers.
The Gradle Version
It’s basically the same technique for Gradle, you just tell standard-version to hit your build.gradle file;
npx @dwmkerr/standard-version --packageFiles build.gradle --bumpFiles build.gradle
There’s an accompanying sample project at:
github.com/dwmkerr/java-gradle-standard-version-sample
This is the same as the Maven version in that the master branch has no standard-version code or changelogs, just open the release branch to see what it looks like after we’ve applied the same techniques as we did to the Maven version.
That’s It
There’s a whole world of libraries for this. commitizen which helps you write conventional commit messages for example. But I found very little for Java. If you find this useful, please do chip in on the pull request here:
https://github.com/conventional-changelog/standard-version/pull/591
As it would be great to add it to the mainline. I’m also just finishing off the update which adds support for Gradle.
As always, questions, comments, suggestions, rants, anything are welcome!