In this article I’m going to give a brief overview of some techniques to build ’least privilege’ roles in AWS. This assumes a basic knowledge of AWS and Identity and Access Management. It uses the (at time of writing) newly announced features in the AWS IAM Access Analyser
I’ll be demoing the techniques using a project built on The Serverless Framework but you don’t need to know anything about how this framework works to follow the article - it is just used to demonstrate the concepts. You should be able to apply these techniques to almost any process which accesses or manages AWS resources.
Let’s get into it!
Updates to the AWS IAM Access Analyser
AWS recently announced some new features to the IAM Access Analyser, which are designed to help build ’least privilege’ policies for your AWS solutions. As I have been deploying a number of solutions based on The Serverless Application Framework I thought this would be a great time to try out these new features.
The Serverless Application Framework is a useful framework if you want to rapidly create serverless applications. You can rapidly create lambda functions, deploy to AWS, test locally, debug and so on.
Our Use Case - A Serverless Framework Deployment Process
When you use the Serverless Framework, a common pattern for deployment is to let the framework itself deploy resources.
A deploy command would look like this:
serverless deploy --stack uat
Under the hood, this will do a few things:
- Create a CloudFormation template which defines an application stack
- Upload the template to an S3 bucket on a specified AWS account
- Deploy the stack
Now what is deployed is very dependent on what you decide to use in your application, but common resources would be things like:
- CloudFormation Stacks
- Lambda Functions
- API Gateway resources
- DynamoDB tables
- SQS Queues
- …and many more!
This raises some interesting questions - how should we secure this provisioning process?
Fundamental Principles - Isolation and Least-Privilege
There are two fundamental principles1 which make sense to consider when thinking about how to integrate the Serverless Framework into your stack:
- Isolation of Resources: Can we make sure that the stack resources are logically isolated from other resources we are managing? This can reduce the impact of incidents - if the stack is compromised, it should only compromise specific resources, not all resources in your estate
- Least Privilege: Can we make sure that when the
serverlessbinary deploys resources, it has the least permissions required to do its work, again reducing the impact of a potential incident
Isolation of resources can be handled in a number of ways - my preferred approach is to create separate AWS accounts for each application (and in fact, each environment, such as ‘dev’, ’test’ and so on). This is not something I will discuss in this article. What I would like to focus on is the second point - least privilege.
Least Privilege in AWS
We don’t quite know what the Serverless Framework does when it provisions resources. I don’t mean this in a bad way. We could investigate and read in detail exactly what happens, but part of the benefit of the framework is that it takes care of this for you2. In the early stages of a project this is probably a great time saver - in the later stages it represents a potential vulnerability.
We understand that it creates a CloudFormation stack, but some of the details are not necessarily readily discoverable from the documentation.
If we wanted to create a policy which represents the permissions which the Serverless we could try a few approaches:
- Give the process full access to an environment, with wide permissions to create any resources
- Give the process limited access to an environment, run the provisioning process, see the permissions issues which arise, then iteratively add more permissions
You might think that the first instinct of a security team might be that a ‘full access’ approach is fundamentally wrong. But great security experts balance risk, agility, cost all the time. They don’t want to stop experimentation - just make sure that it is done in a safe way.
The first approach is perfectly fine in low sensitivity environments. If you want to move fast and try out the technology, you could lose valuable time trying to get the permissions just right. If you have a solid approach to isolation, then you should be able to run your proof of concepts in an isolated sandbox environment, which has no access to sensitive resources.
You can also add Billing Alerts, or even automate the destruction of resources at a certain point, so that you automatically ‘clean up’. This is great security practice - provide teams with a way to experiment safely. Give teams full access to their own self-serve sandbox environments, with automated guardrails to mitigate the risk of incidents2.
Beyond the Sandbox
The ‘sandbox environment’ approach can be valid. But there will likely come a stage when this is no longer appropriate.
When you want to deploy into an environment which has other resources, sensitive data, is accessible to the public, runs production workloads and so on. There will likely come a point where you cannot fully isolate your application - at this stage we should be looking at improving our security.
Specifically, at this point we really should try to make sure that we limit the permissions of the process which runs the serverless deploy command.
Limiting the permissions has the benefit of reducing the ‘blast radius’ of an attack. If the process is compromised it can do fewer things. It also has the benefit of increasing transparency - we will explicitly document what we expect the process to do. This is highly useful when performing security checks.
The Challenges of Limiting Permissions
The process of working out the specific permissions required for a process can be challenging. It might involve looking through lots of documentation, trying to build a policy, seeing if the process works, adding permissions, changing permissions and so on.
Just this month AWS released some updates to the IAM Access Manager, adding some features to help build ’least permission’ policies:
These features immediately caught my eye as I’m very interesting in security practices. We’re going to take a look at these features in detail for the rest of the article and see how we can use them to improve the security of a process like our ‘serverless deployment’.
Using the IAM Access Analyser to Build Fine-Grained Policies
The process for generating fine grained policies with the IAM Access Analyser is quite simple:
- Ensure you are using CloudTrail to track access to resources
- Create an Access Analyser
- Run the process you want to create fine-grained permissions for, initially with wide permissions
- Use the Access Analyser to generate a policy based on the events in CloudTrail
- Refine the policy
- Document, document, document
I’m going to demonstrate this end-to-end with a ‘serverless framework deployment’ process. Please keep an eye out for an article I’ll be writing soon on how to build a REST application with the Serverless Framework - for now don’t worry about the application itself too much, this could be any kind of deployment or operational process we’re running.
Step 1: Enable CloudTrail
We need to enable CloudTrail so that we have a log of API calls which Access Advisor can analyse.
Warning: if you trying these features out please be aware that they may fall outside of the AWS Free Tier and so may incur a cost. Please be aware of this if you are testing these features.
Open the CloudTrail portal and ensure that you have a trail setup which logs API calls. Once this is setup you should see something like this:
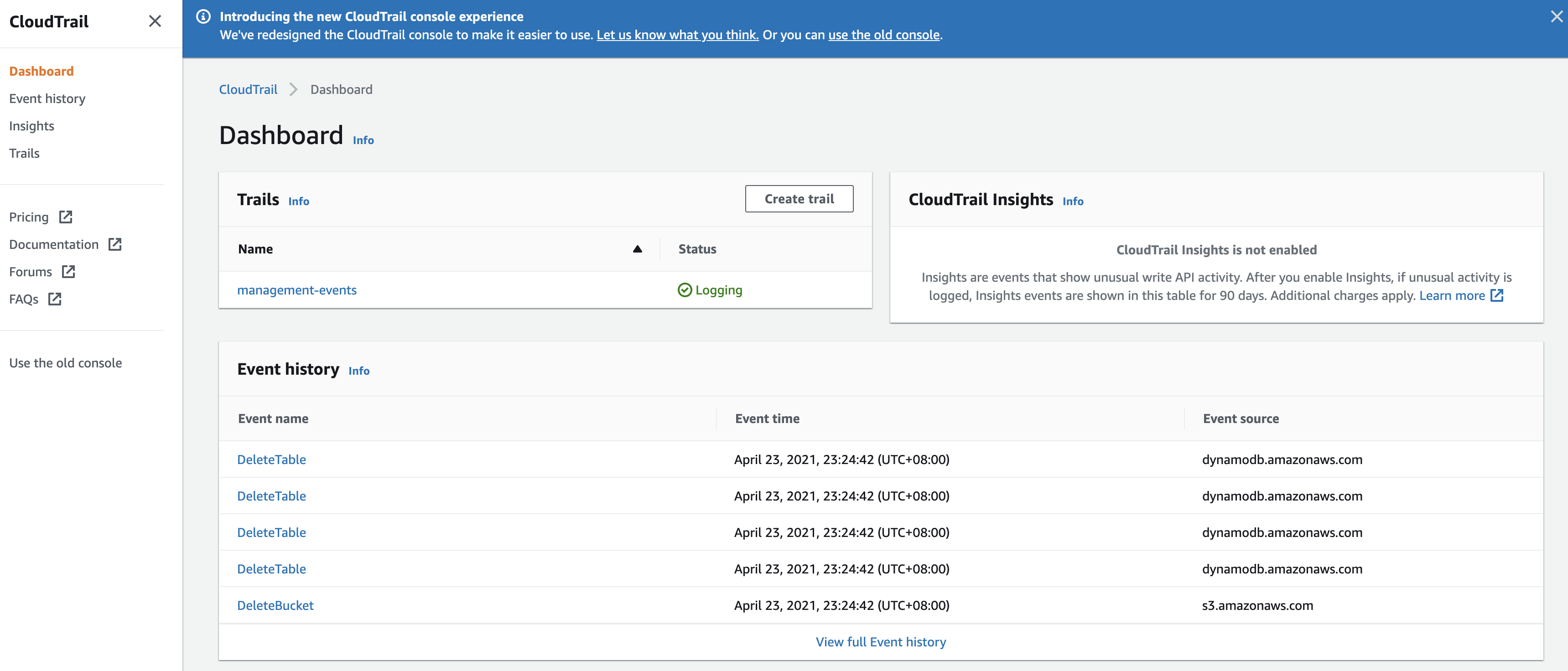
You can use the code below as an example of how to create a trail:
aws cloudtrail create-trail \
--name management-events \
--s3-bucket-name cloudtrail-account123-management-events-bucket \
--is-multi-region-trail
Note that if you don’t use the --is-multi-region-trail flag then the trail is created for the current region only.
You can read more about this command on the Using create-trail documentation page.
Step 2: Create the Access Analyser
You should be able to find the Access Analyser tool in the IAM page:
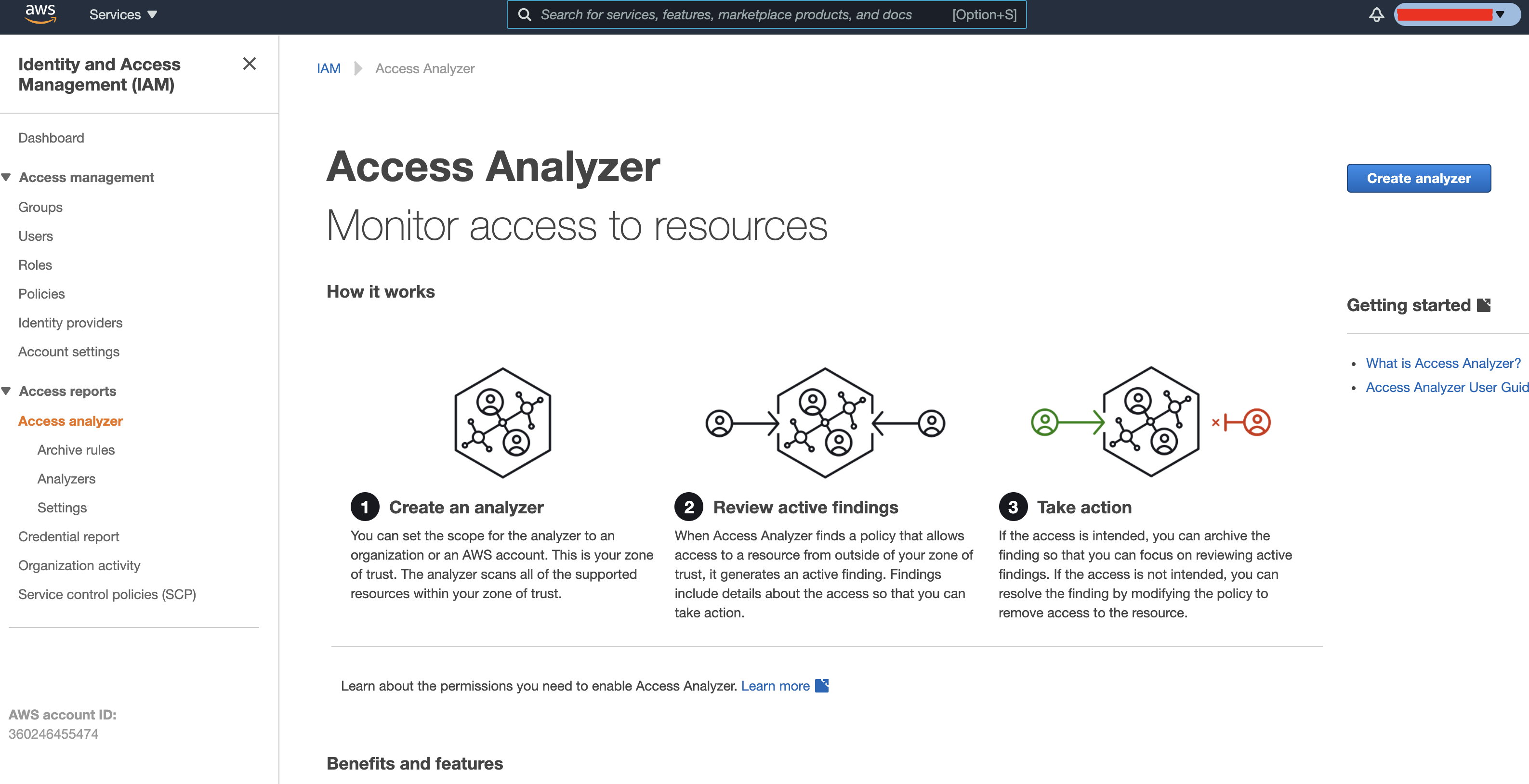
You can now choose to create an analyser. Some things to note:
- Analysers are region specific - if you have many regions, you need many analysers
- You can provide a name, not surprising, but it might be useful to be highly descriptive here
- You have an option to specify the ‘zone of trust’ - this might be an account or an entire organisation
Choose ‘Create Analyser’ to create the access analyser.
You’ll shortly see the created access analyser and likely some ‘findings’ as well:
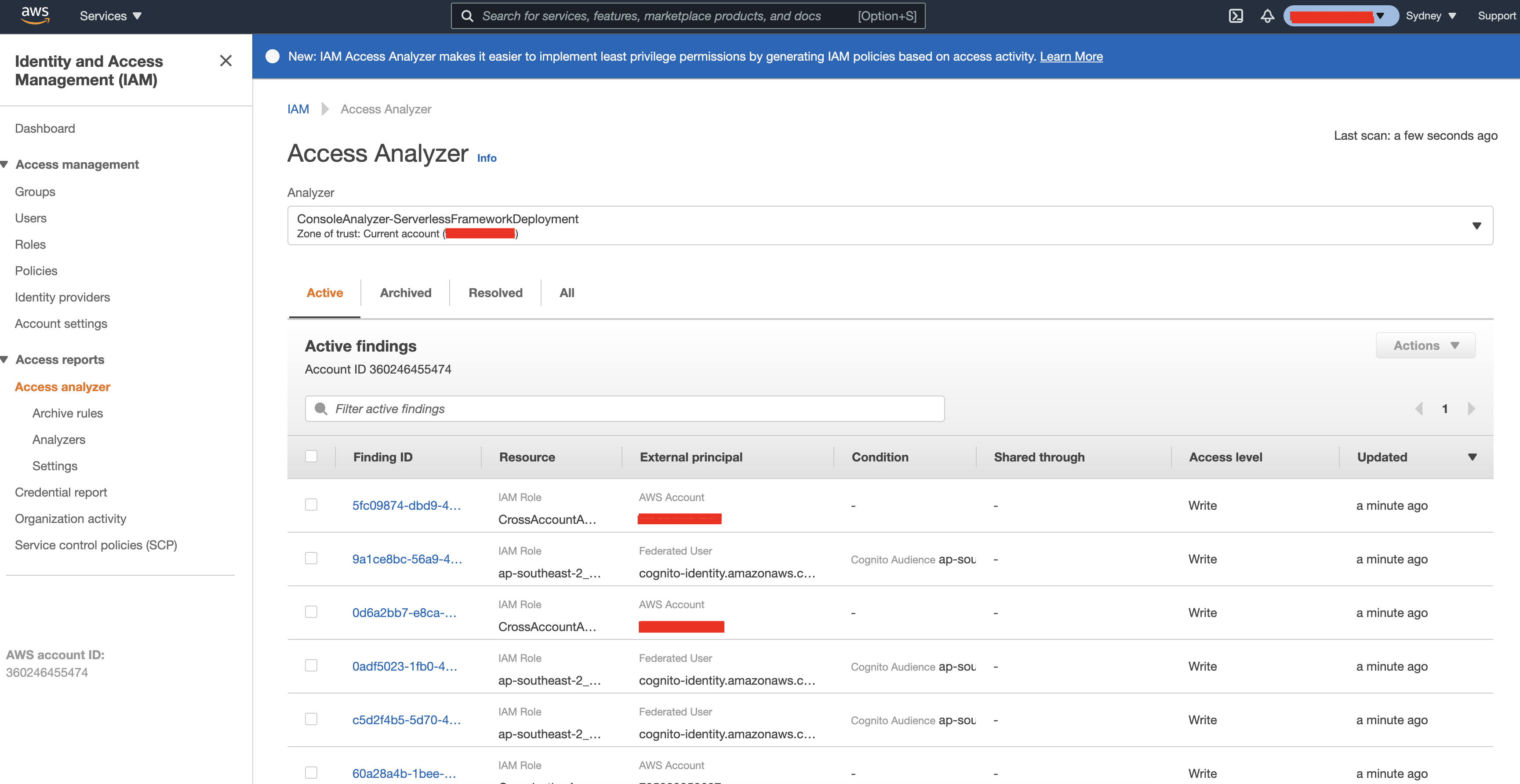
‘Findings’ are the descriptions of the policies that grant access to a resource to a principal which is outside of your zone of trust. This is a quite complex topic, there are more details on the Access Analyser findings documentation. But we are essentially seeing that my policies are set up in a which is exposing my resources to principals outside of the defined zone of trust - these findings are entirely correct, as I have set up Cross Account Access in this environment.
Feel free to read more about findings - these findings can potentially be very useful for a security team to be aware. For now we’ll leave these findings alone and move onto the next step in creating fine grained policies, which is to run the process we want to secure.
Step 3: Run your process
Now you should run the process you want to create fine grained permissions for. To save rework, try and make sure you run all part of the process which will be needed. For example, my Serverless Framework policy should cover creation of the stack, updating of the stack as well as deleting.
To exercise this, I just need to run the following commands from my local project:
# This command deploys a new stack...
serverless --stage dev deploy
# This command makes a change to a file, allowing us to update the stack...
echo "// testing a change to the stack..." >>> lambda_functions/my_function.js
serverless --stage dev deploy # this will update the stack
# This command deletes the stack, we then reset the changes to the file.
serverless --stage dev remove # this will destroy the stack
git checkout lambda_functions/my_function.js
At this point you can run any process your want to secure. As CloudTrail is enable, API calls will be recorded.
Step 4: Create a Policy based on Access Advisor
Now we get to the interesting part. Open the Roles view in AWS, select the role which is used when running your process and choose ‘Generate Policy’. Here’s how this will look in the portal:
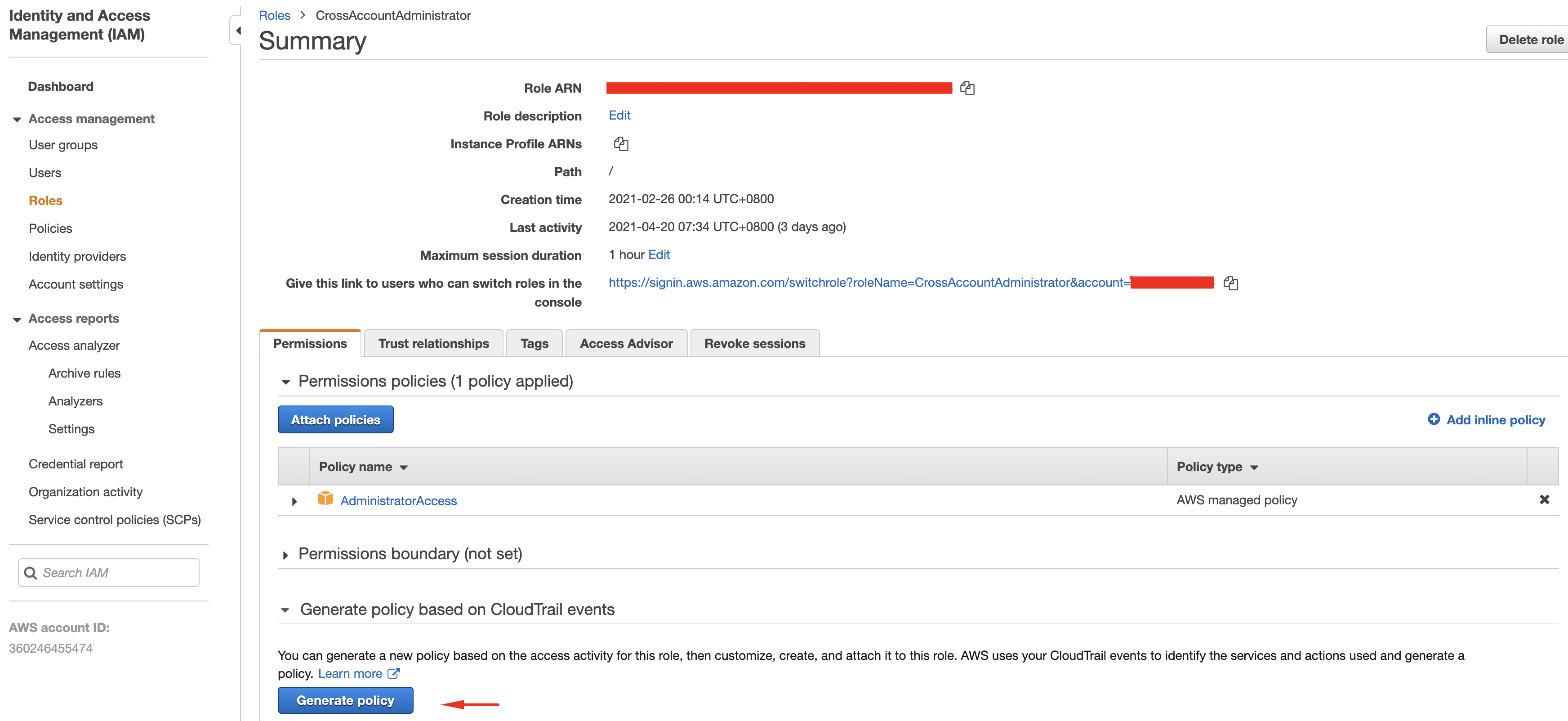
Note that this screenshot shows exactly why fine grained permissions are so important. I have run the Serverless Framework deployment from my local machine using the ‘Cross Account Administrator’ role. This is an extremely high-privilege role which is used when I administer AWS accounts which are part of my organisation. This is not an appropriate role for the Serverless Framework binary to assume outside of a sandbox or proof of concept context. However - remember at this stage we want to use a high-privilege role so that the process runs to completion, so that we can see the permissions needed and then create a more refined role.
When you choose to generate a policy, you’ll have the option of specifying which trail to use and which region. You can also choose a date range for events to analyse. It will be a lot easier to build an appropriate policy if you make this window as short as possible - so try and run the entire process you want to create a policy for and then immediately generate the policy.
It can take a few minutes to generate the policy. When it is complete, you’ll see the option to view the generated policy:
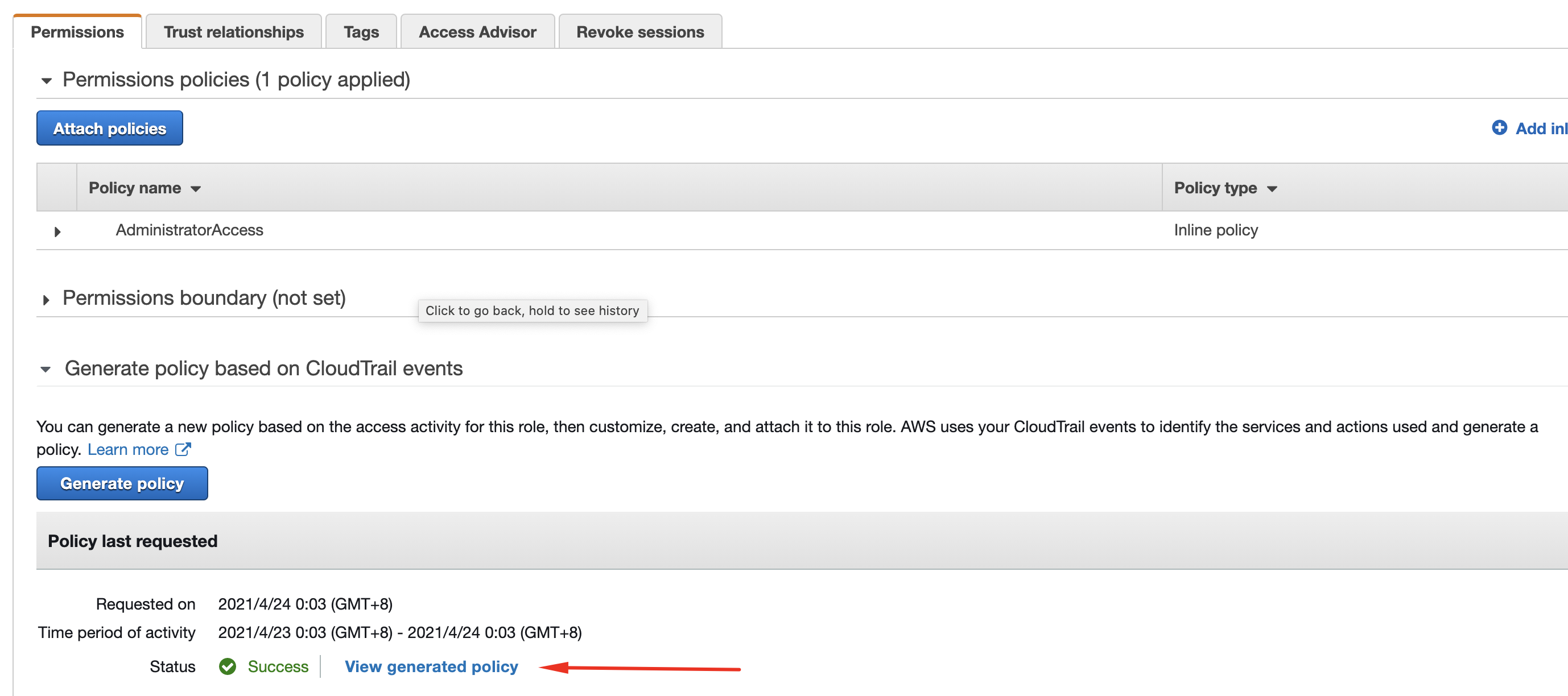
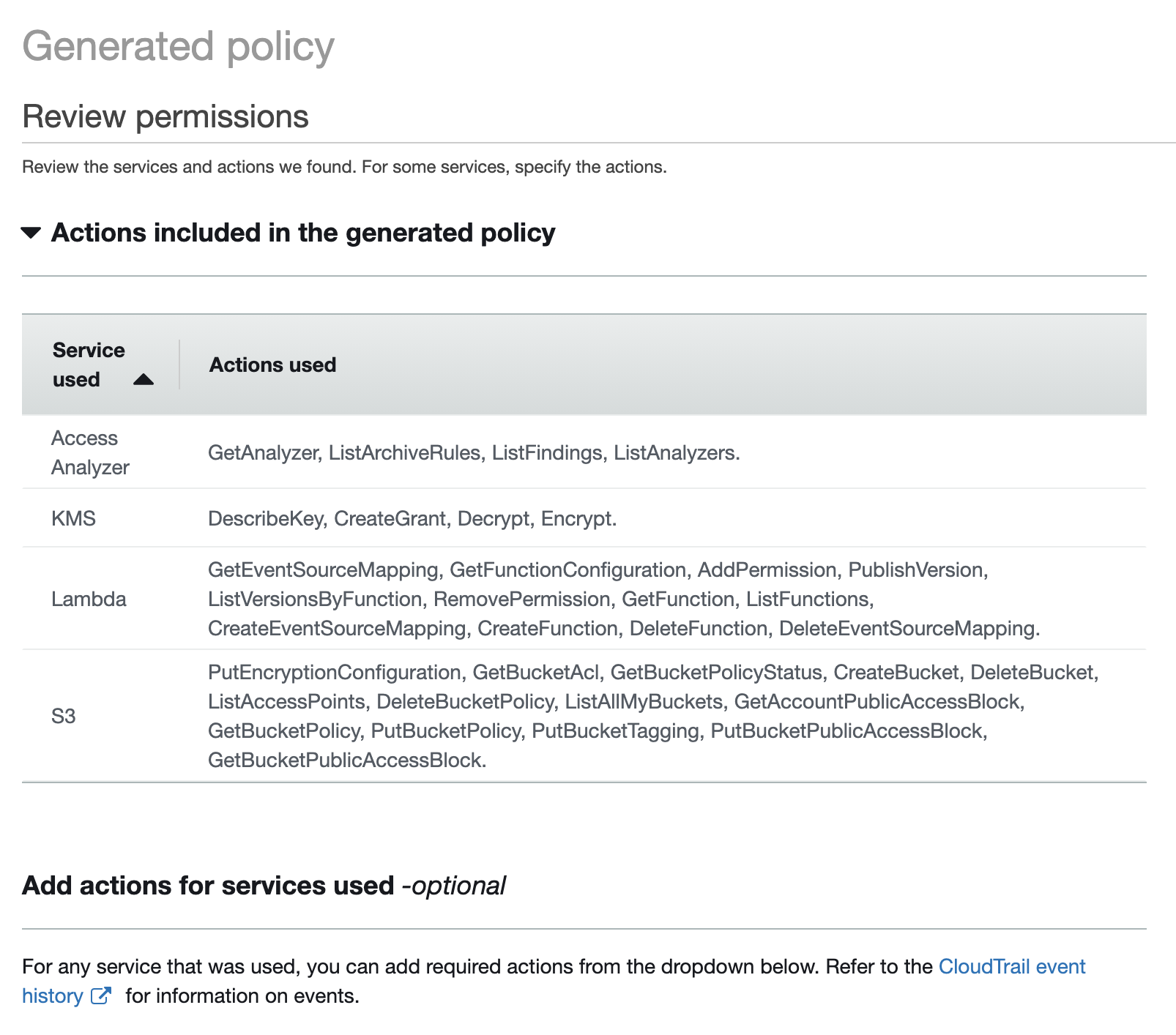
Opening it up, you’ll see the services and actions used, as well as options to add more actions:
When you move to the next screen you’ll get the option to customise the permissions:
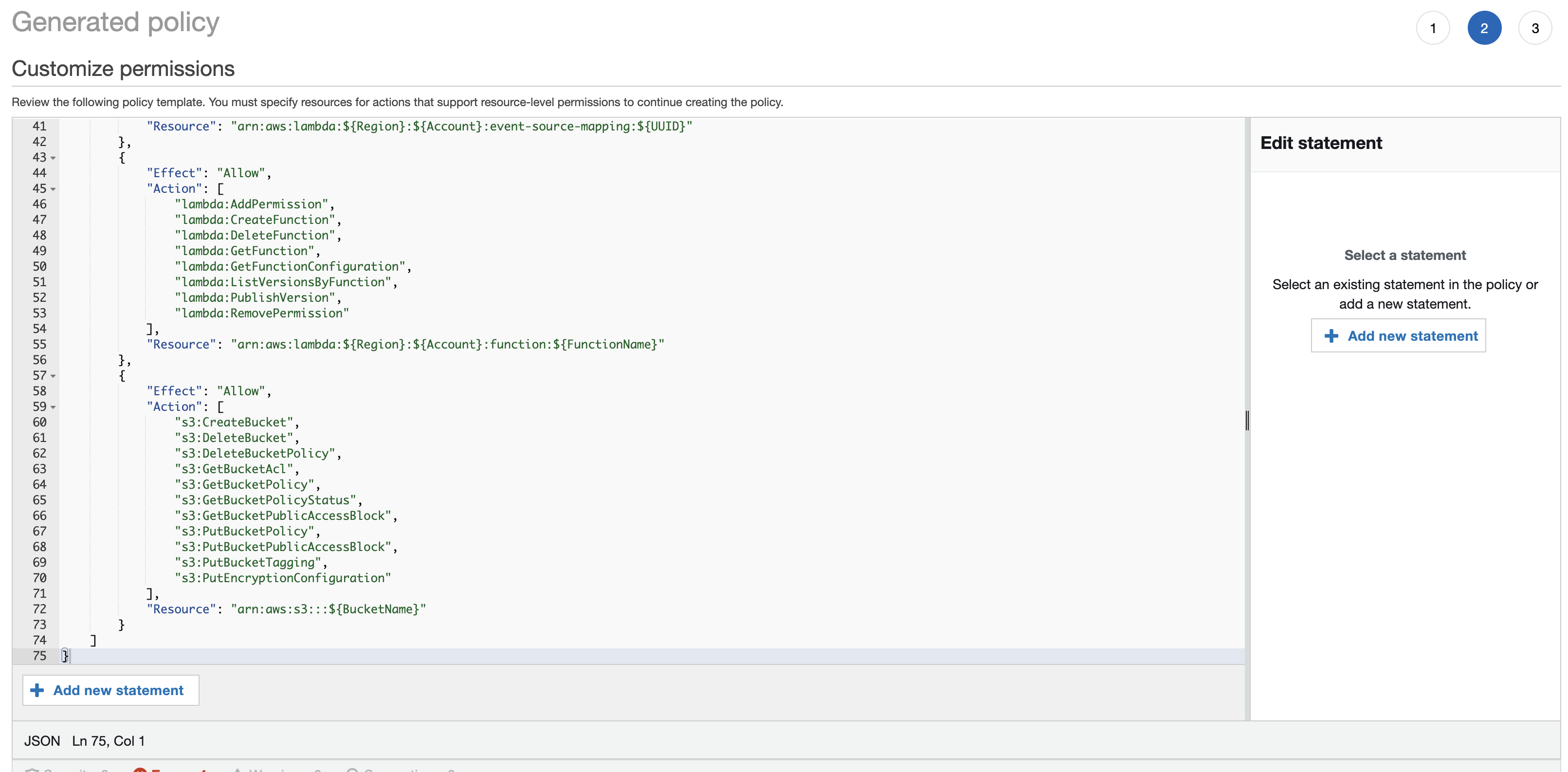
At this stage I would suggest copying the policy, saving it to a local file and then moving onto the next step - refining the policy.
Step 5: Refine the Policy
The generated policy will likely not be suitable for use yet. It might to too specific - limiting access to the specific resources which were used. You will also have services and actions listed for any calls which have been made using the role - which might also include calls used for other processes than just the one you tested earlier. For example, my policy has some permissions to list analyzers. That is not needed by serverless - that has been included because I was using the same cross-account administrator role to create the analyzer earlier on, and this has been picked up.
This also highlights the importance of using separate roles for separate processes - if you use a small number of roles to do a lot of different things, it can be very hard to understand why certain actions were taken. Again, for a quick test it might be OK to use the same role that you access the portal with, but it is good to get into the habit of quickly creating roles for specific purposes.
This is where I would suggest going through the policy in detail and using it as a template for the ‘final’ policy. This is what we’ll discus in the final step.
Step 6: Document, Document, Document
The final policy we create should be clearly documented. It is really important to explain why certain permissions are needed. If people cannot reason about why a policy is set up in a specific way, then it will be very hard for them to maintain it over time or decide whether the permissions are appropriate or not.
Even more so than with ’normal’ code, code which relates to security has to be comprehensible by others (or yourself when you come back to it). If you cannot understand why a policy grants a certain permission, then when you review the policy you don’t know whether the remove the permissions or leave them in (this is an example of Chesterton’s Fence.
Whether you document this policy by saving it in a file, adding comments and checking it into source control, or turning it into a re-usable Terraform module, or using Pulimi to define the policy, or some other solution, is not too important. What is important is documenting the policy and making this documentation transparent to others - and ideally making sure that others can maintain it over time.
As an example, this is how I might define the S3 permissions in a Terraform file:
# This statement allows the creation and management of buckets, which are used
# by serverless for CloudFormation files. Because the bucket name is
# non-deterministic we have to allow the creation of _any_ bucket.
statement {
sid = "ServerlessFrameworkS3"
effect = "Allow"
actions = [
"s3:CreateBucket",
"s3:DeleteBucket",
"s3:DeleteBucketPolicy",
"s3:GetBucketAcl",
"s3:GetBucketPolicy",
"s3:GetBucketPolicyStatus",
"s3:GetBucketPublicAccessBlock",
"s3:GetEncryptionConfiguration",
"s3:GetObject",
"s3:ListBucket",
"s3:PutBucketPolicy",
"s3:PutBucketPublicAccessBlock",
"s3:PutBucketTagging",
"s3:PutEncryptionConfiguration",
"s3:PutObject",
"s3:SetBucketEncryption",
]
resources = [
"arn:aws:s3:::*"
]
}
I’m being very explicit with my comments, giving the statement id a meaningful value and creating separate statements for each service.
How you structure your policies will depend on the tools you use and your own preferred processes but the principle will remain the same - document carefully!
That’s It!
The IAM Access Advisor is a powerful feature and should be of interest to anyone managing sensitive environments in the cloud.
It is not limited to creating fine grained permissions - it can also help identify external access to resources. This means it can be used to identify when resources such as S3 buckets are accessed via processes such as Cross-Account access.
There are a lot of exciting features here and it will be interesting to see how the Access Advisor works over time!
As usual, please do share any comments, suggestions or observations!
Of course this is only a tiny part of the world of security best practices. To learn more I highly recommend Veeral Patel’s amazing ‘How to secure anything’ project ↩︎
The exact permissions required are documented at https://serverless-stack.com/chapters/customize-the-serverless-iam-policy.html ↩︎ ↩︎